
Eliminating the Data Blind Spots in Spare Parts Supply Chains
This article presents a technical, end-to-end framework for identifying and eliminating data blind spots in spare parts supply chains, linking fragmented part data to asset criticality, maintenance execution, and sourcing decisions
Master Spare Parts Data to Avoid Stockouts and Unplanned Downtime
Spare parts supply chains sit at the intersection of engineering, maintenance, procurement, and operations. They are critical to asset availability and business continuity, yet they are often the least visible and least optimised part of the industrial supply chain.
Unlike direct materials, spare parts demand is irregular, failure-driven, and highly asset-specific. Parts may sit unused for years, only to become urgently required during a breakdown where downtime costs can exceed the value of the part by several orders of magnitude. Despite this operational importance, spare parts data is frequently fragmented, unstructured, and disconnected from the assets and failure modes it is meant to support.
These conditions create data blind spots – the areas where parts technically exist in systems, but lack the visibility, structure, and context required for effective decision-making. The result is excess inventory, unnecessary downtime, emergency sourcing, and limited return on automation and predictive maintenance initiatives.
Why Spare Parts Supply Chains Are Structurally Complex?
Spare parts supply chains differ fundamentally from production supply chains due to several inherent characteristics:
Long-tail demand distribution:
Spare parts demand follows an extreme long-tail pattern. Industry studies consistently show that over 90 – 95% of spare part SKUs are slow-moving or intermittently used, whilst a very small subset accounts for the majority of consumption. This makes traditional forecasting models ineffective and increases the risk of both excess inventory and critical stock-outs. Unlike production materials, demand is driven by failures rather than predictable schedules.
Long asset lifecycles:
Industrial assets often remain in operation for 20–40 years, far exceeding the lifecycle of OEM part numbers, supplier contracts, or ERP implementation. This creates ongoing challenges related to obsolescence, sourcing continuity, and supersession tracking.
Engineering-driven definitions:
Spare parts are defined by form, fit, and function, not by commercial identifiers alone. However, procurement and ERP systems are typically SKU-centric. This mismatch becomes problematic when the same functional part exists under multiple material numbers or supplier references. Without structured technical attributes, organisations struggle to identify equivalency, leading to duplicate inventory and fragmented spend visibility.
Interchangeability and supersession:
Across asset generations, upgrades, and supplier changes, multiple parts may fulfil the same functional role. Yet supersession relationships are often poorly documented or manually maintained. This drives premium pricing, expedited freight, and reactive decision-making.
High consequence of failure:
The operational impact of spare part unavailability far exceeds the part’s unit cost. A missing low-cost component, such as a bearing, seal, or sensor, can shut down high-value equipment. Industry analyses indicate that spare part availability issues contribute to as much as 30 – 40% of unplanned downtime events in asset-intensive environments. In these cases, downtime costs can reach thousands or even hundreds of thousands of pounds per hour, making data accuracy and availability mission-critical.
These characteristics make spare parts fundamentally different from production materials and require specialised inventory planning and control approaches that balance demand variability against stock costs and service levels. For a broader overview of what effective inventory management looks like in practice, see this comprehensive guide.
A Technical Overview of Spare Parts Data Domains
To understand where blind spots emerge, it is important to examine the core data domains involved in spare parts supply chains:
- Part Master Data: Includes material numbers, descriptions, manufacturer references, and basic classifications stored in ERP systems. This data is often created locally and inconsistently across sites. These inconsistencies are often a direct outcome of weak inventory creation, numbering, and tracking discipline at the procurement and stores level.
- Technical Attribute Data: Covers dimensions, materials, performance ratings, tolerances, and environmental limits. These attributes are critical for interchangeability and substitution but are frequently unstructured or missing.
- Asset and Maintenance Data: Stored in EAM/CMMS systems, this data links parts to equipment, maintenance history, failure modes, and usage patterns. In many organisations, this linkage is weak or incomplete.
- Supplier and Lifecycle Data: Includes supplier availability, lead times, pricing, obsolescence status, and supersession relationships. This data is rarely synchronised across systems.
Inconsistent master part creation drives poor visibility and duplicate records. Inventory visibility challenges arise in modern operations when naïve stock records lead to excess or obsolete stock, see this discussion on common warehouse issues and inventory visibility.
Persistent Data Blind Spots in Spare Parts Supply Chains
Spare parts supply chains face structural data gaps that limit visibility and increase operational risk. These blind spots prevent organisations from accurately tracking inventory, substitutions, obsolescence, and the criticality of parts.
A data blind spot occurs when spare parts data exists but cannot reliably answer questions such as: Do we already have the part? Is there an acceptable alternative? Which assets depend on it, and how critical is it? Is it obsolete, superseded, or still required?
These gaps can be grouped into following key areas:
Fragmented and Inconsistent Part Definitions
When the same physical part exists under different identifiers across systems and plants, it prevents central visibility and intelligent decision-making. Each system may have its own version of a part with free-text descriptions, causing identical parts to be treated as unique SKUs.
For example, a bearing might appear multiple ways in the system (e.g. “Ball Bearing 6205-2Z,” “SKF 6205ZZ”), leading to unnecessary stock build-up and confusion. Without consistent naming conventions or unique identifiers, planners frequently order parts already on hand in another location.
Without normalisation, none of these are recognised as the same item. This leads to duplicate inventory sitting idle in one location whilst another plant orders a replacement, driving both excess stock and stock-outs.
This issue is widespread: poor naming and duplicate records are cited as a primary data quality challenge in parts management, causing inventory confusion and unnecessary spending (Source: Sparrow Parts).
Missing or Unstructured Technical Attributes
Critical characteristics, such as dimensions, material, operating ratings (pressure, temperature, voltage), and tolerances, are often not captured in structured, machine-readable fields. Instead, they reside in PDF datasheets, free-text descriptions, or siloed spreadsheets.
For instance, two valves may both be labelled “pipe valve,” but one is rated for 150 PSI and the other for 600 PSI. In an emergency, a planner might assume a substitution is acceptable, but in reality, the incorrect valve could catastrophically fail under pressure.
Poor Linkage Between Parts, Assets, and Work Orders
In many organisations, procurement, maintenance, and engineering systems are not integrated, which breaks essential traceability.
- ERP systems hold procurement and inventory data.
- EAM/CMMS systems record work orders and maintenance history.
- PLM systems hold design specifications.
This lack of integration highlights the importance of maintenance systems that connect assets, work orders, and spare parts consumption in a single operational view.
When systems lack shared part identities or fail to link parts to assets and work orders, organisations cannot identify which parts are consumed most frequently, whether usage is preventive or reactive, or which failures drive costs.
Limited Visibility into Obsolescence and Supersession
Spare parts become obsolete due to product upgrades, supplier discontinuations, or design changes. Yet those changes are often not propagated cleanly into ERP and inventory systems.
Research on spare parts lifecycles indicates that only approximately 2% of parts are in the early phase of their lifecycle, whilst a combined ~45% are in end-of-manufacturing or end-of-life stages, making them difficult to source and manage.
Managing this challenge requires lifecycle-aware inventory practices that account for aging assets, supplier discontinuations, and replacement strategies.
For example, a control module for a legacy machine may no longer be manufactured by the original supplier. If supersession records, which part replaces it, are not maintained, the inventory system may show stock as available, but the part cannot actually be used. Planners then either scramble for costly emergency orders or incorrectly hold unusable stock.
Absence of Criticality Context
Without linking parts to asset criticality and failure impact, organisations treat all spares similarly, leading to misaligned stocking strategies. Conducting a parts criticality assessment, as covered in this article, allows organisations to prioritise high-risk components over low-impact ones.
As per industry practices, combining ABC analysis (value/usage) with criticality tags (e.g. VED – Vital, Essential, Desirable) helps distinguish high-risk components from low-impact ones and has been shown to free up significant capital tied up in obsolete inventory.
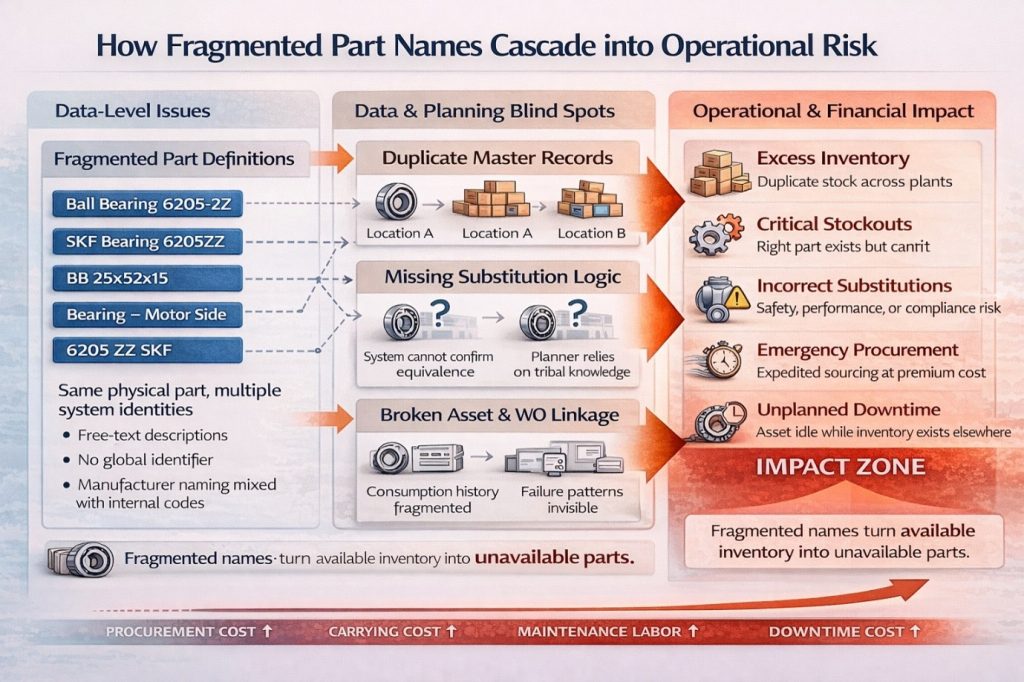
Operational Impact of Data Blind Spots
When these blind spots persist, the operational consequences are significant:
- Inventory inflates: Excess duplicate or obsolete parts tie up working capital and warehouse space.
- Critical stock-outs occur: Parts that actually matter are not located or prioritised properly, leading to emergency orders and downtime.
- Higher costs: Rush shipments and reactive maintenance inflate procurement and labour costs.
Spare parts management inefficiencies can lead to stock that has not moved in 24 months representing 30–50% of inventory, a clear indicator of misaligned data and planning (Source: Throughput).
A Structured Framework to Eliminate Spare Parts Data Blind Spots
Effectively managing spare parts data requires a comprehensive, multi-layered approach that combines standardised data architecture, advanced analytics, and operational integration.
-
Establish a Canonical Spare Parts Data Model
Create a system-independent master record that serves as the authoritative part identity.
- Link internal material numbers, OEM references, and supplier codes.
- Include technical attributes, functional roles, and lifecycle information.
- Ensure a single source of truth across ERP, EAM/CMMS, PLM, and MES systems to support cross-site visibility and analytics.
-
Implement Multi-Dimensional Classification
Move beyond basic procurement hierarchies to classify parts along multiple dimensions:
- Functional: purpose within the asset or system
- Physical: size, material, pressure/temperature ratings, tolerances
- Application-Based: operating conditions, criticality, and failure mode associations
This allows for advanced filtering, interchangeability analysis, and predictive maintenance alignment.
-
Enrich and Normalise Data Using AI
Leverage machine learning and natural language processing (NLP) to:
- Extract structured attributes from unstructured text (PDFs, drawings, free-text descriptions)
- Normalise units, naming conventions, and part identifiers
- Detect duplicates and map potential functional equivalents across locations
This enables automated standardisation, reduces SKU proliferation, and improves master data quality.
-
Enable Interchangeability and Substitution Intelligence
Use enriched data and advanced algorithms to:
- Identify form-fit-function equivalents across assets and generations
- Recommend substitute options for unavailable or obsolete parts
- Optimise inventory allocation across sites and minimise emergency procurement
This supports resilient sourcing strategies and improves overall spare parts availability.
-
Close the Loop with Maintenance Execution
Integrate spare parts data with asset and maintenance execution systems to:
- Map parts to specific assets, work orders, and failure modes
- Differentiate planned versus reactive consumption
- Inform predictive maintenance strategies and improve forecasting accuracy
This ensures that operational insights drive inventory optimisation and procurement planning.
Organisations often benefit from adopting established inventory and supply chain best practices as a foundation for these advanced data and analytics initiatives.
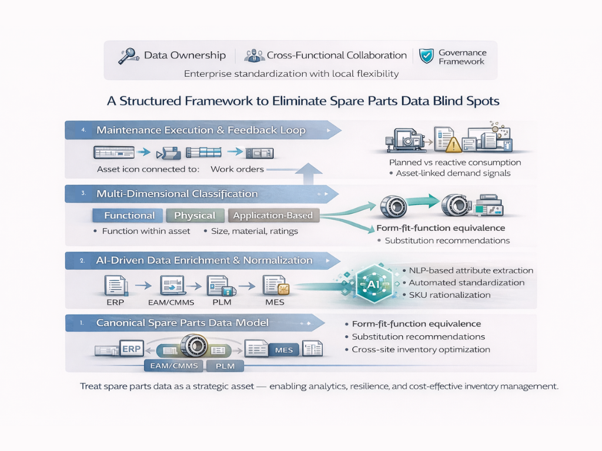
Organisational and Governance Considerations
Technical solutions alone are insufficient; success depends on governance and cross-functional alignment:
- Data Ownership: Assign clear responsibility for spare parts master data at the enterprise level.
- Cross-Functional Collaboration: Align engineering, maintenance, procurement, and IT teams to ensure consistency and operational relevance.
- Governance Framework: Implement policies that balance enterprise standardisation with site-level flexibility for local operational constraints.
Treat spare parts data as a strategic asset, enabling advanced analytics, operational intelligence, and cost-effective inventory management, rather than as a transactional by-product.
Conclusion
Spare parts supply chains are complex by nature, with irregular demand, long asset lifecycles, and high consequences of failure. When part data is fragmented or lacks context, these challenges escalate into excess inventory, downtime, and reactive sourcing.
A structured framework built on canonical data models, multi-dimensional classification, AI-driven enrichment, and tight integration with maintenance execution eliminates these blind spots and restores visibility.
Combined with strong governance, this approach turns spare parts data into a strategic asset, enabling leaner inventories, higher asset availability, and more resilient operations.